1.kafka 创建日志主题
# 创建主题 kafka-topics --bootstrap-server gfdatanode01:9092 --create --replication-factor 3 --partitions 1 --topic nginxlog
2.flume 收集日志写到 kafka
创建 flume 到 kafka 的配置文件 flume_kafka.conf,配置如下
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type=exec a1.sources.s1.command=tail -f /var/log/nginx/access.log a1.sources.s1.channels=c1 #设置Kafka接收器 a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink #设置Kafka地址 a1.sinks.k1.brokerList=172.16.122.23:9092 #设置发送到Kafka上的主题 a1.sinks.k1.topic=nginxlog #设置序列化方式 a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder a1.sinks.k1.channel=c1 a1.channels.c1.type=memory a1.channels.c1.capacity=10000 a1.channels.c1.transactionCapacity=100
启动 flume
flume-ng agent -n a1 -f flume_kafka.conf
3.python 读取 kafka 实时处理
通过 python 实时处理 nginx 的每一条日志数据,然后写到 mysql 。
from kafka import KafkaConsumer servers = ['172.16.122.23:9092', ] consumer = KafkaConsumer( bootstrap_servers=servers, auto_offset_reset='latest', # 重置偏移量 earliest移到最早的可用消息,latest最新的消息,默认为latest ) consumer.subscribe(topics=['nginxlog']) for msg in consumer: info = re.findall('(.*?) - (.*?) \[(.*?)\] "(.*?)" (\\d+) (\\d+) "(.*?)" "(.*?)" .*', msg.value.decode()) log = NginxLog(*info[0]) log.save()
4.数据分析可视化
数据都准备好了,分析就很简单,直接通过 sql 就可以查出想要的数据了。
数据量比较大时,加上适当的索引可以提高查询效率。
-- 用户分布 select province, count(distinct remote_addr) from fact_nginx_log where device <> 'Spider' group by province; -- 不同时段访问情况 select case when device='Spider' then 'Spider' else 'Normal' end, hour(time_local), count(1) from fact_nginx_log group by case when device='Spider' then 'Spider' else 'Normal' end, hour(time_local); -- 最近7天访问情况 select case when device='Spider' then 'Spider' else 'Normal' end, DATE_FORMAT(time_local, '%Y%m%d'), count(1) from fact_nginx_log where time_local > date_add(CURRENT_DATE, interval - 7 day) group by case when device='Spider' then 'Spider' else 'Normal' end, DATE_FORMAT(time_local, '%Y%m%d'); -- 用户端前10的设备 select device, count(1) from fact_nginx_log where device not in ('Other', 'Spider') -- 过滤掉干扰数据 group by device order by 2 desc limit 10 -- 搜索引擎爬虫情况 select browser, count(1) from fact_nginx_log where device = 'Spider' group by browser;
最后,通过 pandas 读取 mysql,经 ironman 进行可视化展示。
基于 flask 和 echarts 的数据可视化工具 ironman
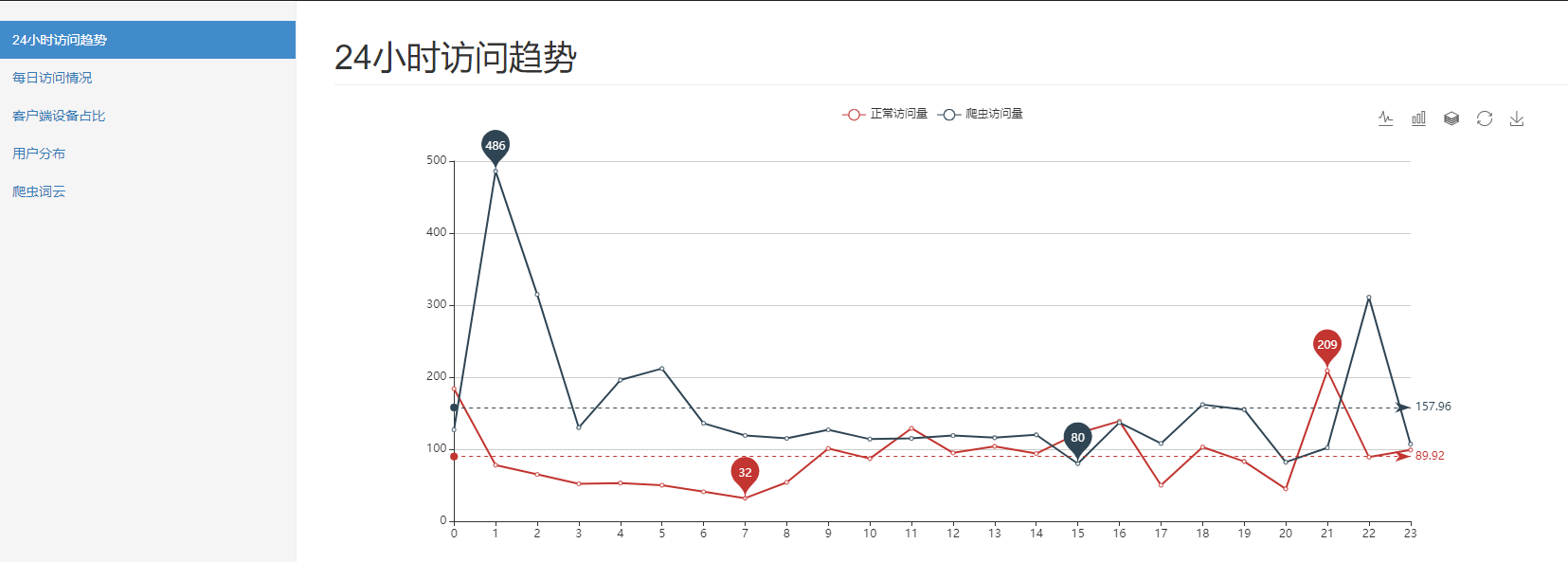
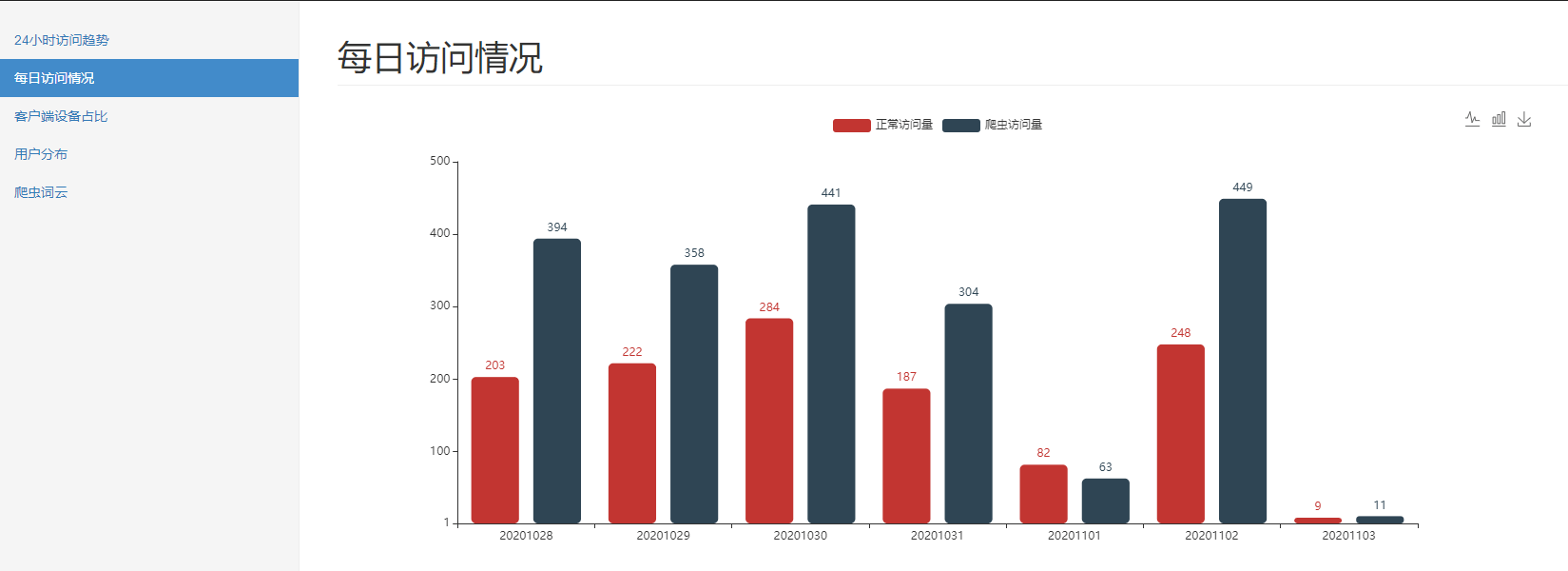
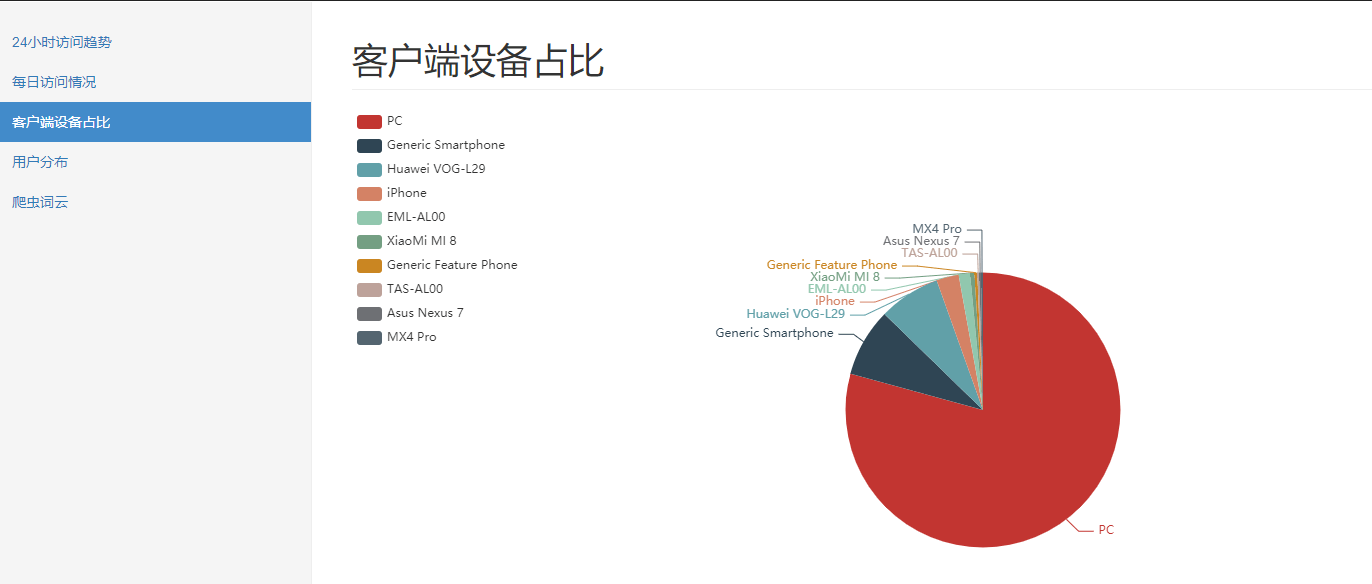
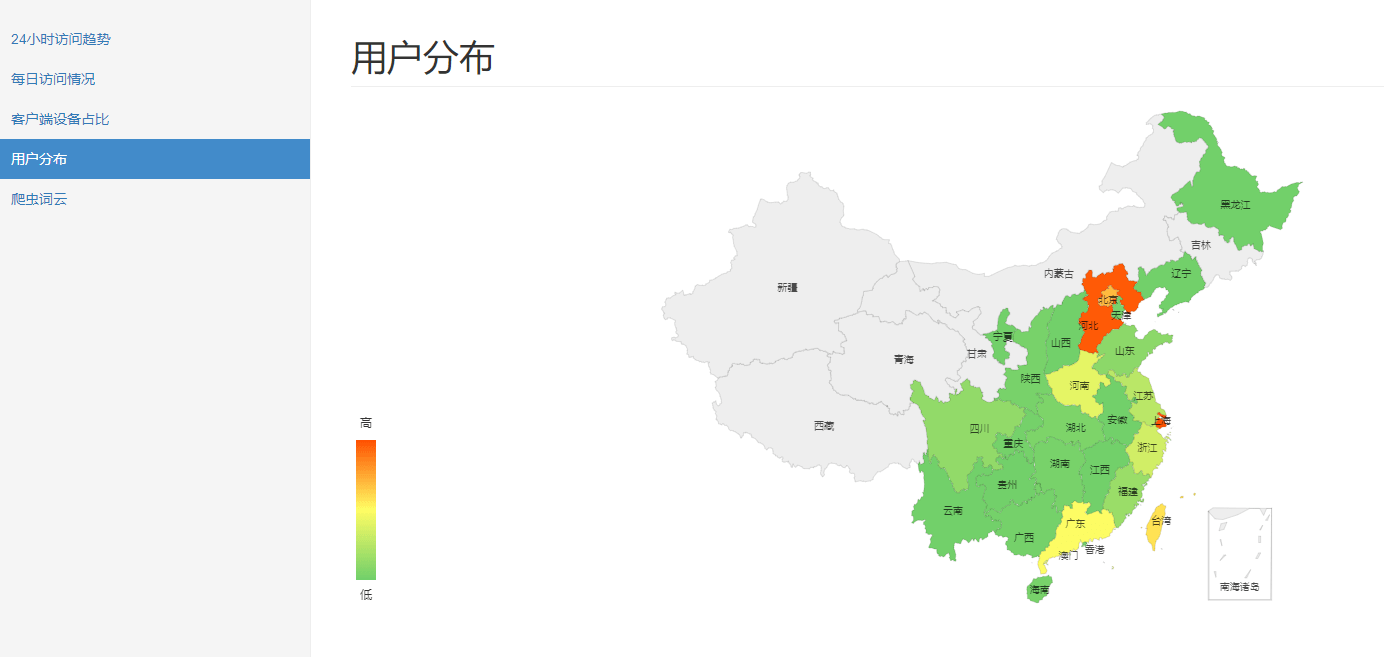
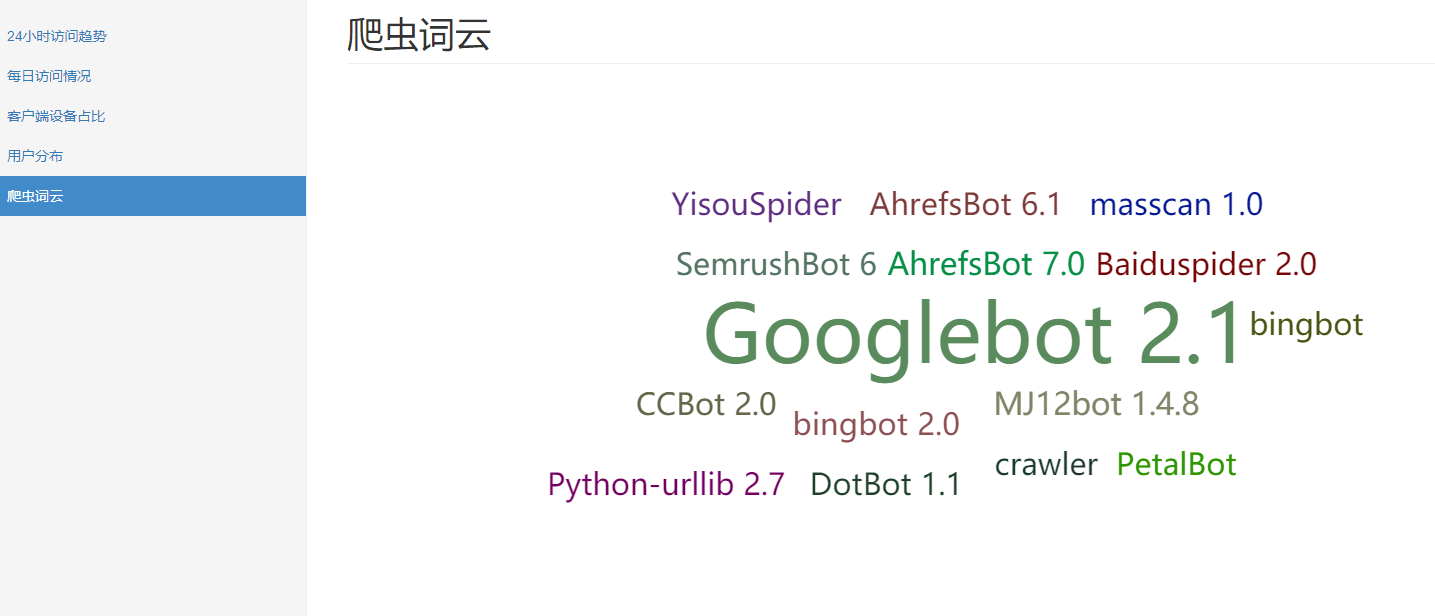
5.总结和思考
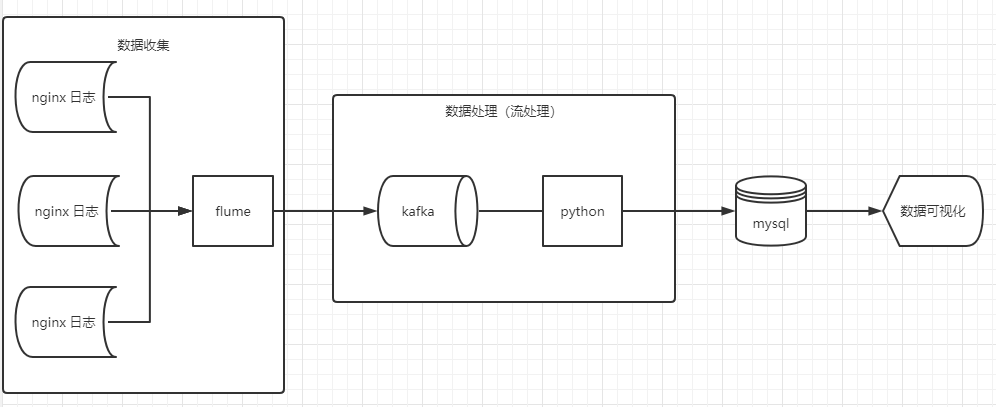
整体来看,这个处理过程的优势有以下几点:
- 实时性:流处理,实时性高。
- 处理:使用了 kafka 集群作为消息管道,即使高并发也可以轻松应对。
缺点则在于:
- 运维:kafka 数据是直接存在宿主机器的,不像 hdfs 存储。所以数据量积累一段时间后,需要自行扩容硬盘和备份。
可能的瓶颈和优化方向:
-
瓶颈:同上一篇的批处理,mysql 会是瓶颈。此外,真正的数据处理实际是在 python 中完成的,高并发时,会有单机的性能瓶颈,导致吞吐量不高,产生较高的延迟。
-
优化方向:可以引入 flink ,spark 这一类的流处理引擎,将 python 的数据处理任务,提交到处理引擎进行分布式处理。
6.开源地址
https://github.com/TurboWay/bigdata_practice
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:http://blog.turboway.top/article/bigdata_practice_stream/
许可协议:署名-非商业性使用 4.0 国际许可协议




lipengcccc
4 楼 - 4 年前
我配好了,现在知道怎么关主域名,可以了,谢谢大佬,我把两位大佬的博客链接附在我的博客上