1.环境
centos7 + flink 1.10.1 + Hadoop 2.6.0-cdh5.16.1
2.下载软件
2.1 下载flink
# 下载 flink wget https://mirror.bit.edu.cn/apache/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz # 解压 tar -zxf flink-1.10.1-bin-scala_2.11.tgz # 重命名 mv flink-1.10.1-bin-scala_2.11.tgz flink
2.2 集成 hadoop
# 下载 对应版本的 flink-shaded-hadoop.jar wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.5-10.0/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar # 移到到 flink/lib/ mv flink-shaded-hadoop-2-uber-2.6.5-10.0.jar flink/lib/ # 添加 HADOOP_CONF_DIR 环境变量 vi /etc/profile HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop/etc/hadoop
3.standalone 集群模式配置多台机器
3.1 配置 masters
vi conf/masters # 注意端口要和 conf/flink-conf.yaml 的 rest.port 一致,默认 8081
3.2 配置 slaves
vi conf/slaves
3.4 配置 flink 相关参数
vi conf/flink-conf.yaml # 调优参数很多,主要注意下面这两个 jobmanager.rpc.address: gfdatastandby # 需要配置到统一的 master rest.port: 8088 # 默认 8081, 如果端口占用,可以更改此端口
3.5 将 flink文件夹 复制到所有的 slave 机器
scp -r flink root@gfdata07:/opt/soft/
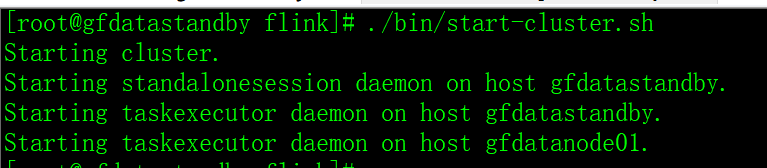
3.6 启动 standalone 集群
./bin/start-cluster.sh
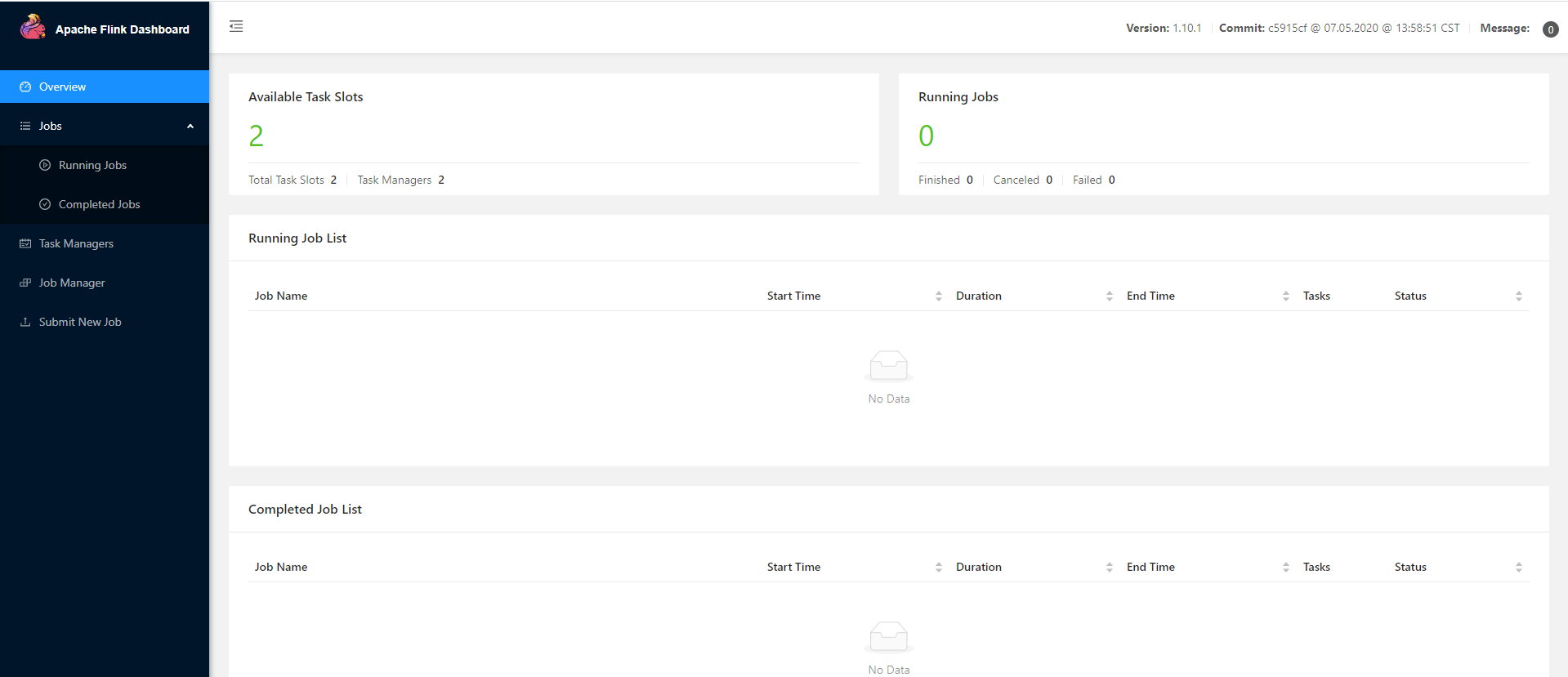
3.7 访问 http://172.16.122.20:8088/

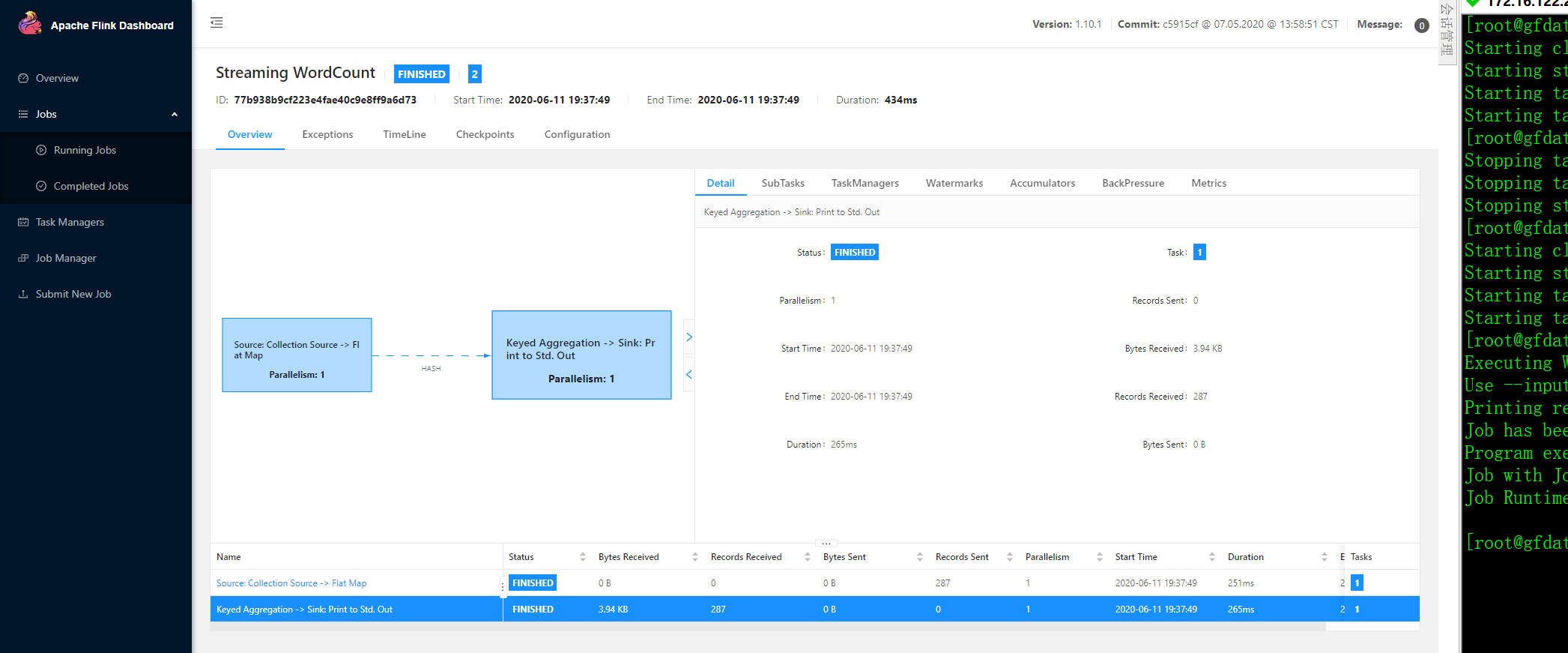
3.8 运行 flink demo
./bin/flink run examples/streaming/WordCount.jar


4.yarn 模式
4.1 standalone 集群模式
启动 standalone 集群
./bin/start-cluster.sh
停止 standalone 集群
./bin/stop-cluster.sh
4.2 yarn-session 模式
./bin/yarn-session.sh -jm 1024m -tm 4096m
4.3 yarn per-job 模式
./bin/flink run -m yarn-cluster -p 4 -yjm 1024m -ytm 4096m ./examples/batch/WordCount.jar
5.flink-sql
# 启动客户端
./sql-client.sh embedded
6.一些注意点
standalone 集群模式配置多台机器的模式下,在 master 运行 yarn-session 、yarn per-job 模式均会报错;在 slave 可以运行 yarn-session 、yarn per-job 模式
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:http://blog.turboway.top/article/flink1/
许可协议:署名-非商业性使用 4.0 国际许可协议

